前言
前一篇介紹了 Ansible 的使用,剛好最近公司的一個情境可以利用 Ansible 來做到,筆者這邊想跟大家分享一下。公司最近採用了 OpenShift 來做整個 k8s solution 的平台管理,進而把公司既有的服務虛擬化放進 k8s 中,但是仍然是屬於一個私有雲的架構,也就是會佈署一個 On-Premise 的 k8s. 那麼如果要做到 High availability,官方文件其實都也有說明了。簡單來說,利用一個所謂的 virtual IP 給進 OpenShift 的 inventory 中,其他事情交給它來 deploy。因此,我們必須先設定好 KeepAlived 這個 service。
最後筆者也會提到,筆者認為真正的 High availability 應該是要由 KeepAlived + HAProxy 來達成,不過每間公司最終都是想要 keep the cost down,可能不想要再多準備額外 server 來做整個 production 的設計 (就像筆者公司),所以像是 Load balancer 或是 Storage node (用來存放registry、NFS 或是 Glusterfs) 這些 server 都是能省則省。以上只是筆者弱弱的 murmur XD。
OpenShift + KeepAlived deployment
Openshift
筆者這邊所使用的是 OKD 3.11,所使用的 tag 是 v3.11.0。OpenShift 目前已到 4.7 (2021/05/13),3 的版本整體架構是利用 Ansible 來做佈署,4 的版本就全然改變,而且使用的 OS 也有限制,必須使用 Red Hat Enterprise Linux CoreOS (RHCOS) (把自己的產品賣好賣滿XDD,太奸詐啦),種種考量之下,最後公司選擇了 3 的版本。
Config KeepAlived
這邊我們可以利用 OpenShift 的 inventory,來針對 control plane 的機器透過 Ansible 來設定 KeepAlived。假設目前我們有三台 master,inventory 就會像是定義成:
1
2
3
4
5
6
7
8
...
[masters]
192.168.0.1
192.168.0.2
192.168.0.3
...
那麼我們就可以利用 Ansible 來寫一個 playbook:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
- name: config keepalived, skip it if there is only one master in the list
hosts: masters
vars:
servers_list: "{{ groups['masters'] }}"
tasks:
- name: Get mgmt interface name and set fact
set_fact:
control_mgmt_intf_name: "{{ ansible_default_ipv4.interface }}"
- debug:
msg: "{{ control_mgmt_intf_name }}"
- name: copy keepalived config to node
template:
src: ../../template/keepalived.conf.j2
dest: /etc/keepalived/keepalived.conf
mode: "0640"
when: servers_list|length > 1
- name: start and enable keepalived
shell: "{{ item }}"
with_items:
- systemctl start keepalived
- systemctl enable keepalived
when: servers_list|length > 1
這邊來說明一下:
-
control_mgmt_intf_name: 這是要用來填在 keepalived.conf 裡面的 interface,讓 VIP 會坐落在此 interface 上。值得注意的事情是,ansible_default_ipv4.interface這個是Ansible預設的值,讀者必須注意這個 interface 是否就是你要的,Ansible是根據 default route 去填這個值,參考這篇。 -
when: servers_list|length > 1: 最後兩個 task 有加這個條件,原因是因為當叢集只有一台 master 的時候並不需要VIP,所以不需要設定KeepAlived。 -
利用
jinja2來產生 config 檔真的十分好用,大推!,詳情可以看Ansible的 template module。 -
最後把
KeepAlivedservice 打開並且 enable 就可以了。
底下是 keepalived.conf.j2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
! Configuration File for keepalived
global_defs {
notification_email {
}
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_k8s {
script "/usr/bin/curl -k https://{{ hostvars[inventory_hostname]['ansible_default_ipv4']['address'] }}:8443/healthz | grep ok"
interval 2
weight 2
}
vrrp_instance k8s-vip {
state {% if inventory_hostname == hostvars[servers_list[0]].inventory_hostname %}MASTER{% else %}BACKUP{% endif %}
priority 50
interface {{ control_mgmt_intf_name }} # Network card
virtual_router_id 102
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
unicast_src_ip {{ hostvars[inventory_hostname]['ansible_default_ipv4']['address'] }} # The IP address of this machine
unicast_peer {
{% for host in servers_list %}
{% if inventory_hostname != hostvars[host].inventory_hostname %}
{{ hostvars[host]['ansible_default_ipv4']['address'] }} # The IP address of peer machines
{% endif %}
{% endfor %}
}
virtual_ipaddress {
{{ k8s_cluster_vip }}/24 # The VIP address
}
track_script {
chk_k8s
}
}
說明:
-
chk_k8s: check script,筆者這邊所使用的是去檢查此台 k8s api server 的 health check,若此台無法 serve k8s api,則 return failed。 -
unicast_src_ip: 本台機器的IP。 -
unicast_peer: 其他台機器的IP,這邊就可以體現到 jinja2 的好用。
以上,Run 完此 playbook 便可以讓你的機器輕鬆設定好 keepalived。
Architecture
KeepAlived on each master node
剛剛上面例子的架構是會將 KeepAlived 的 service 設定在每台 master 上,並且會在這些 master 當中切換 VIP。圖:
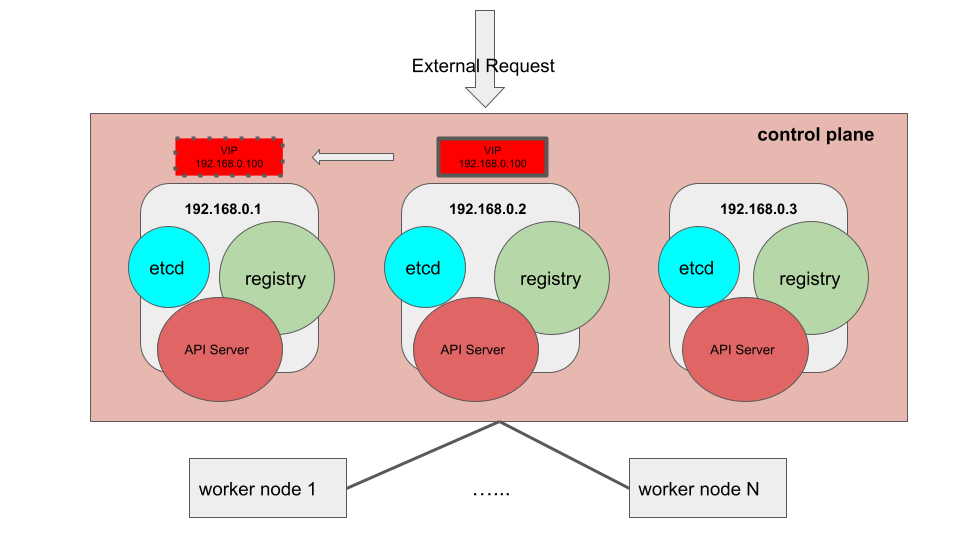
如果有三個 master,每台會存在著 etcd、API server,這些都是 k8s 中基本的 control plane 元件 (有些比較細節的元件,筆者這邊就沒畫出來因為在這邊不會討論到,像是 kube-scheduler 等等的)。首先,這樣子的架構可以容忍 single failure,假設中間的 192.168.0.2 機器掛掉,VIP 假設切換到了 192.168.0.1,那麼剩下的兩台仍會持續運作,但是若再失去任何一台 master,則無法運作因為 etcd 就會出問題,原因詳見這裡。一般官方建議最少需要有三到五台的 etcd。
再來是 registry,因為一開始提到為了 keep the cost down,所以才把 registry 也放置在 master,而 OpenShift 在 deploy k8s 或是帶 pod 的時候,就可以透過 VIP 去拉 VIP 坐落在那台 master 上面的 registry。正常來說應該拿額外的機器來充當 registry,確保 image source 不會與 master 有 dependency。而 worker node 也會透過 VIP 去拉 image 來操作。
KeepAlived + HAProxy
這邊要提到的架構,是筆者認為真正可以做到 High availability:
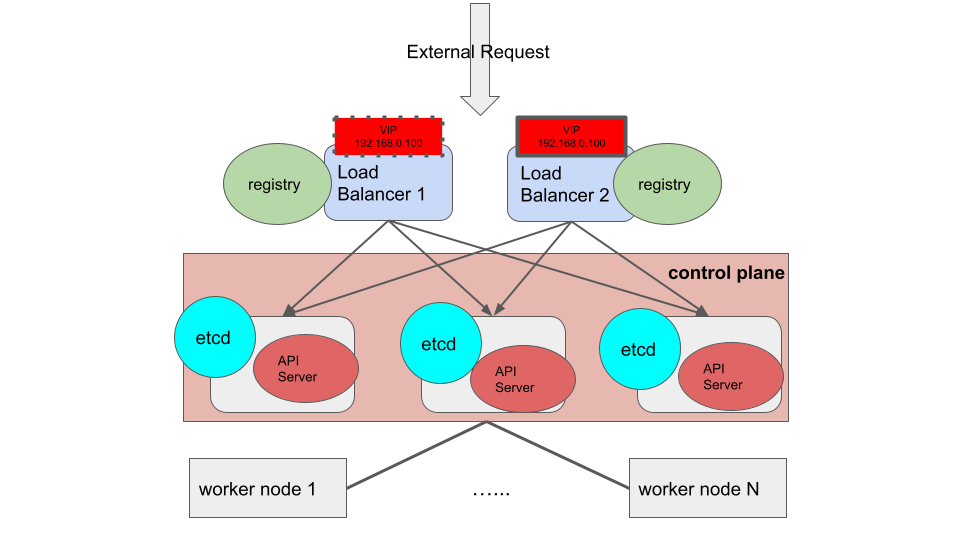
前面會有兩台 Load balancer 在 control plane 之前,上面透過 KeepAlived + HAProxy 將外部 request 分流至每台 master。同時,registry 也放在 load balancer 上面,讓每台 node 都可以透過 VIP 存取 Load balancer 上面的 registry。上圖中,etcd 仍是放在 master 中,若是將 etcd 獨立拉出去變成一個 group,control plane 就算只剩下一台 master 也是可以運作,那麼筆者認為此架構便是可以真正做到 High availability 的精神。透過 OpenShift 的 inventory 都可以做到這種架構,包含指定 Load balancer,etcd 的 group 等等。但誠如筆者前面所說,此種架構就是得多花很多機器的預算,不過這也就是為什麼很多企業傾向用 public cloud 去做 solution 的架構,透過像是 GCP 或是 AWS,管理機器以及佈署會變得較為簡單而且成本比實際的硬體 server 會便宜一點。
總結
OpenShift 是一個方便佈署以及管理 k8s 的平台,我們透過 Ansible 去設定 KeepAlived 來達到切換 VIP 的作用,讓其中一台 master 掛掉的話使 control plane 可以持續運作。
Contact me
有任何疑問或是建議歡迎聯絡 Jimmy!
Gmail: jimmyw86878@gmail.com
-
Previous
Ansible - Ansible cluster sandbox for testing, scaling and learning your playbooks -
Next
Gitlab docker setup and use LDAP for authentication